My attempt to run Gemma AI model locally
Recently, Google/Deep Mind announced Gemma:
A family of lightweight, state-of-the art open models built from the same research and technology used to create the Gemini models
I was curious if I could ever run these models on a local server. Gemma features both a 7B and a 2B token model, so I thought I'd have a shot on one of my cheap 4-CPU Intel servers that has 16GB of RAM.
The 2B parameter model, at 2 Bytes / token, should be around 4GB.
2 x 1024 x 1024 x 1024 tokens x 2 Bytes / token = 4,294,967,296 Bytes
Downloading the model
I'm following the instructions on the Kaggle page.
I also had to download my Kaggle API token
into ~/.kaggle/kaggle.json. This was required in order to run the Keras option below.
Keras
The first option is to use the Python keras
package, which I've used in the past.
The total space taken by the model is 4.7G.
Python setup:
pyenv install 3.10.10
pyenv virtualenv 3.10.10 gemma-keras
pyenv activate gemma-keras
pip install --upgrade keras-nlp-nightly
# Alternatively, from https://github.com/keras-team/keras-nlp
# pip install --upgrade keras-nlp
# pip install --upgrade keras>=3
Sample script: gemma.py. I needed to create this script inside the downloaded model
directory
import keras_nlp
gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma_2b_en")
print(gemma_lm.generate("Keras is a", max_length=30))
I needed to create and run this script inside the downloaded model directory, or
I would see errors when importing the keras_nlp library in python.
When this script was run the first time, it re-downloaded the 4.7G model into a new directory--super annoying.
~/.cache/kagglehub/models/keras/gemma/keras/gemma_2b_en/2/model.weights.h5
Invoking the script:
$ time python gemma.py
Keras is a popular deep learning library for Python. It is easy to use and has a wide range of features. One of the features of
real 1m38.011s
user 1m52.609s
sys 0m17.086s
So it took 98 seconds to produce 30 words, including the model load time. Ha! I was surprised that it finally worked. Not all the other methods worked out.
Flax
I also tried the Flax option, because this page
said that it could be run with either a CPU, GPU or TPU.
I downloaded the 2b model, which takes 3.7GB:
$ du -sh
3.7G .
Python setup:
pyenv install 3.10.10
pyenv virtualenv 3.10.10 gemma
pyenv activate gemma
pip install git+https://github.com/google-deepmind/gemma.git
Invoking the sample script
git clone https://github.com/google-deepmind/gemma.git
cd gemma
python examples/sampling.py \
--path_checkpoint=../model/2b/ \
--path_tokenizer=../model/tokenizer.model \
--string_to_sample="Where is Salt Lake City?"
which looked good at first:
Loading the parameters from /home/schaubj/work/jschaub30/gemma/model/2b/
I0223 14:37:24.434225 135111827680128 checkpointer.py:164] Restoring item from /home/schaubj/work/jschaub30/gemma/model/2b.
I0223 14:37:34.196148 135111827680128 xla_bridge.py:689] Unable to initialize backend 'cuda':
I0223 14:37:34.196315 135111827680128 xla_bridge.py:689] Unable to initialize backend 'rocm': module 'jaxlib.xla_extension' has no attribute 'GpuAllocatorConfig'
I0223 14:37:34.198884 135111827680128 xla_bridge.py:689] Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: libtpu.so: cannot open shared object file: No such file or directory
I0223 14:37:34.299071 135111827680128 checkpointer.py:167] Finished restoring checkpoint from /home/schaubj/work/jschaub30/gemma/model/2b.
Parameters loaded.
...but crashed after about 30sec with this helpful error message:
Killed
I decided to run my viz_workload profiler to try and uncover any problems.
The results are here.
The memory profile immediately stood out:
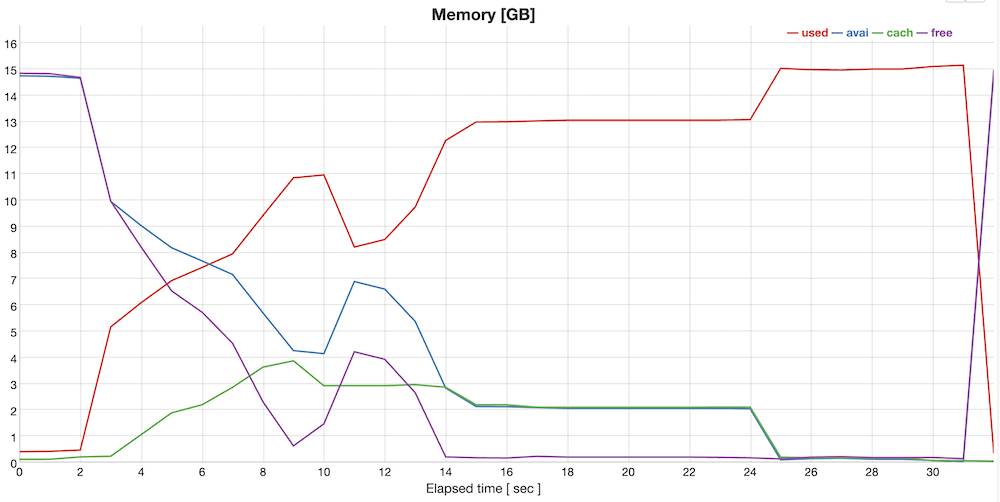 .
.
The used memory (in red) peaked at 15.1 right when the workload crashed.
I then checked the dmesg log and saw many memory related errors:
[ 330.616577] Out of memory: Killed process 2646 (sampling.py) total-vm:24639840kB, anon-rss:15396924kB, file-rss:256kB, shmem-rss:0kB, UID:1000 pgtables:35264kB oom_score_adj:0
Transformers
The transformers description looks promising:
A transformers implementation of Gemma-2b-instruct. It is a good choice for Python developers that want a quick and easy way to prompt a model, or even begin developing LLM applications. It is a 2B parameter, instruction-tuned LLM.
The downloaded model size was
$ du -sh
15G .
This is too large--maybe a mistake?
The setup is easy enough:
pyenv virtualenv 3.10.10 gemma-transform
pyenv activate gemma-transform
pip install --upgrade pip
pip install transformers
pip install torch # not documented! Took forever
Sample script--I modified it to add the access API token.
from transformers import AutoTokenizer, AutoModelForCausalLM
with open(".token", "r") as fid:
access_token = fid.read().strip()
# tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b-it", token=access_token)
tokenizer = AutoTokenizer.from_pretrained("google/", token=access_token)
model = AutoModelForCausalLM.from_pretrained("google/", token=access_token)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids, max_new_tokens=30)
print(tokenizer.decode(outputs[0]))
Invoking the script:
$ time python gemma.py
Loading checkpoint shards: 100%|█████████████████████████████████████████████████| 2/2 [00:02<00:00, 1.47s/it]
<bos>Write me a poem about Machine Learning.
Machines, they weave and they learn,
From the data, they discern.
Algorithms, a symphony,
Unleash the power of
real 0m28.090s
user 1m12.143s
sys 0m22.906s
So this is much quicker than keras (28 seconds for 18 words).